# DATASTRIDE TOOL DOCS
This document describes the workflow of the Datastride tool on the backend site. These features of the tool include:
- Automatically pull the latest data from input table to output_table
- Allow get campaigns of organization, update
custom group, CPMfields on UI, filter campaigns by fields which serve for BI analysis.
# How to tool work
# With admin
Admin user is responsible for:
- Onboarding for org_id
- Establishing a job to synchronize data from the input table (radar) to the output table (datapal).
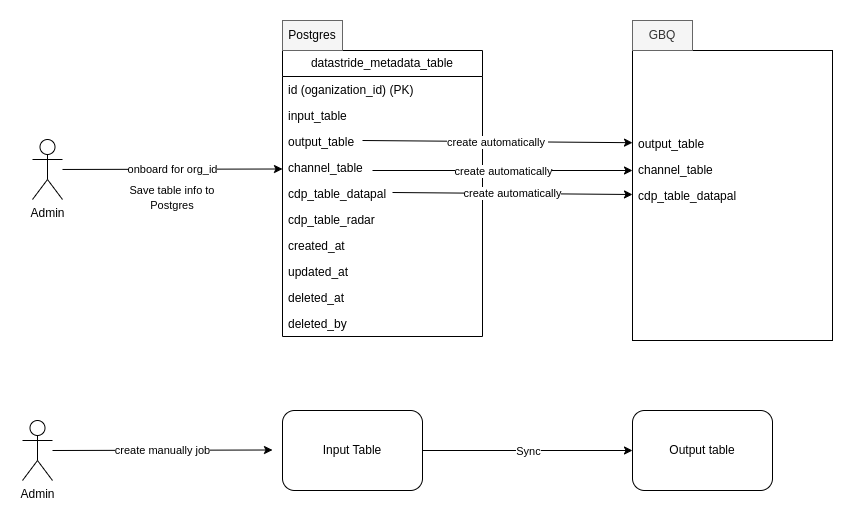
Onboard steps:
- In this step, the admin performs onboarding for the org_id, store necessary tables which tool work on in PostgresSQL
- Simultaneously, creating automatically tables on Google BigQuery (GBQ) for that org_id.
- Example:
{
"input_table": "radar-377104.operations.true_datastride_campaign_entity_master_union",
"output_table": "radar-377104.operations.true_datastride_campaign_entity_master_union_output",
"channel_table": "radar-377104.operations.datastride_channel_table",
"cdp_table_radar": "radar-377104.radardata.advantage_media_orders",
"cdp_table_datapal": "radar-377104.operations.datastride_cdp_table_datapal"
}
- In above fields:
input_table, output_table, channel_table, cdp_table_datapalis required fieldscdp_table_radaris optional
=> When onboarded, if table of channel_table, cdp_table_datapal, output_table fields don't exist, they will be automatically created in GBQ.
Sync steps:
- This step will synchronize data from the input table provided by Radar to the output table that the Datastride tool works on.
- Below are the fields will be updated by the Datastride tool if there are any changes from the
input table.
campaign_total_budget,
campaign_start_date,
campaign_end_date,
daily_budget,
channel,
placement,
TMID,
order_number,
vendor_name,
current_month_start_date,
current_month_end_date,
current_month_gross_budget,
current_month_net_budget,
current_month_plan_impressions,
billed_bill_amount,
billed_net_amount,
plan_impressions,
platform_commission,
- Fields will be updated by Users on UI:
custom group
CPM
- Notes:
- Key is used to sync data from input table --> output table of tool is
account_id, campaign_id, TMID, order_number, placement - These changes will be reflected in the
output tableat the top of each hour by the job onCloud Scheduler
- Key is used to sync data from input table --> output table of tool is
# Detailed onboard step
| N.o | Steps | Person in-charge | Notes |
|---|---|---|---|
| 1 | Prepare agency information, which includes agency name, parent agency (if existing),... | Agency Representative | |
| 2 | Add the agency to Authentication Service | * Datapal Authen admin tool (if exist) * Or, Datapal Admin/Developers | This step results in a unique org_id |
| 3 | Add agency's users to Authentication Service | * Datapal OAuth2 login Button on UI (if exist) * Datapal Authen admin tool (if exist) * Or, Datapal Admin/Developers | Add the users (requested by user directly or by the agency's representative) to organization id org_id generated in step 2. |
| 4 | Provide BigQuery table ID where the tool will pull data. Provide BigQuery table ID where the working data will locate in. | Agency Representative | Make sure the tables are granted to be used by Datapal. |
| 5 | Provide Account List for the agency. | Agency Representative | The list should be in a CSV file, having 5 columns: platform, account_name, account_id, client_code, description. |
| 6 | Tell the tool that the organization (step 3) will use data from the BigQuery table ID (step 4, input table) and will filtered by the account list (step 5). Also specify output table ID, where the working data will locate in. | * Admin tool (in development) * Developers (manually) | In case of doing this step manually, execute two below commands:curl -X 'POST' 'https://<TOOL_API_URL>/admin/onboard/<ORGANIZATION_ID>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"input_table": "string","output_table": "","channel_table": "","cdp_table_radar": "","cdp_table_datapal": ""}'* Then init the account list in the Account Mapping Service. No matter how many time we call the API for the same account list. The API will do de-duplication before insertion. curl -X 'POST' 'http://<ACCOUNT_MAPPING_API_URL>/admin/migrate-accounts/<ORGANIZATION_ID>' -H 'accept: application/json' -H 'Content-Type: multipart/form-data' -F 'file=@<PATH_TO_ACCOUNT_CSV_FILE>;type=text/csv' |
| 7 | Schedule a job to transfer data from input table to output table ID | * Datapal Admin/Developers | * Schedule using Cloud Scheduler. - Developers provide an API endpoint (specificalize for each tool to sync data). Admin/Develops will config Cloud Run to call to the API periodically. With data stride tool, using below API https://<TOOL_URL>/admin/view-to-table?view_id=<input_table_id>&table_id=<output_table_id>* Schedule using BigQuery Query Scheduler. In each code folder for every tool, developers include SQL code to synchronize data. Schedule a job to execute this code using the BigQuery Query Scheduler. |
| 8 | Notify user to use the tool by accounts created in step 3 | * Agency Representative * Mail center |
# With user
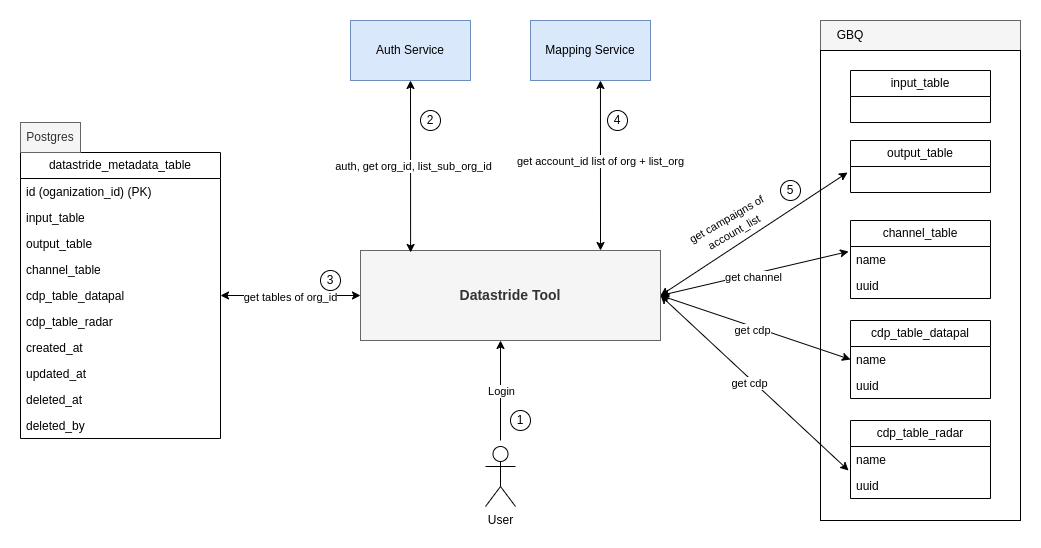
- User login to tool
- If user login successfully, the Datastride tool will authenticate the account.
- If authentication is successful, the
auth servicewill return the org_id and list_sub_org_id (if available) of the account. - Example:
{
'username': 'datapal@yopmail.com',
'nickname': 'datapal@yopmail.com',
'organization_id': '8b56174a-9aea-4775-af80-0f9958baaed6',
'organization_name': 'datapal',
'sub_org_id': None,
'sub_org_name': None,
'sub_org_id_list': ['3ce13528-9418-4d00-acbd-79f100f9c36d', '906ed1b8-19a9-448e-a079-95afb61f9f31', 'c8dd10ea-b74a-485c-81fd-6898d0140c85']
}
- Utilizing the org_id obtained from step 2, retrieve the relevant tables stored in PostgresSQL that the tool operates with.
- In case the account is not onboarded, logging into the tool will result in no available data.
- Leveraging the
org_id + list_sub_org_idobtained in step 2, the tool will retrieve the account_list corresponding to the combined identifiers from the mapping service. - Using the account_list acquired in step 4 and the tables obtained in step 3, the tool will gather all campaigns associated with the logged-in account's account_list.
# Onboarding Workflow for Datastride tool
Param for API onboard:
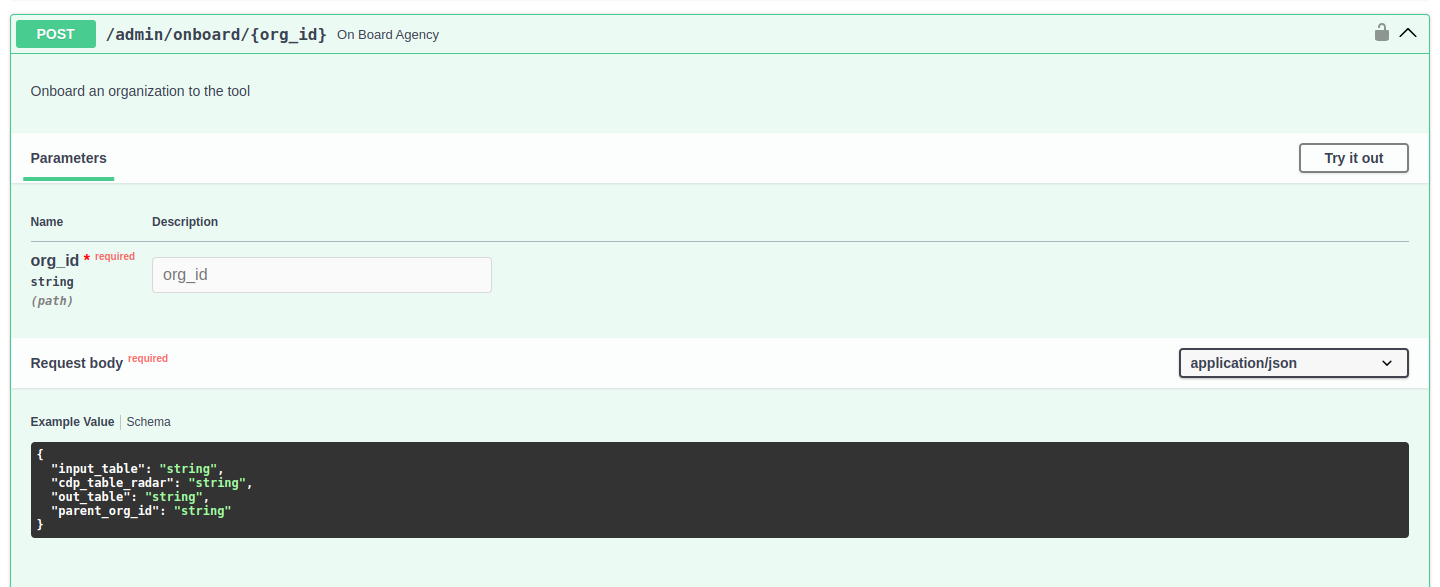
In these params:
org_idinput_table,cdp_table_radaris required fieldsout_tableparent_org_idis optinal fields
# Onboarding logic:
Firstly, check whether the passed org_id has the same parent_org_id passed in.
- If
parent_org_idis passed along withorg_id
- Check if
parent_org_idis onboarded or not in metadata table of CTG. If it has not yet been onboarded, BE side will raise an error -> onboard fororg_idfailed - If
parent_org_idonboard, BE side will use information about tables ofparent_org_id-> insert new rows including tables oforg_idin postgres metadata -> onboard successfully.
- If
parent_org_idis not passed -> Now,org_idis parent_org When onboarding fororg_id, the following tables will be automatically initialized
out_table
cdp_table_datapal
channel_table
=> The names of these tables will be generated and created by the BE side
if out_table is passed in API, BE side will use this name to create out table instead of using out_table name which generated