# Conversion Mapping Tool Backend
Features:
Allowing users update Conversion Group, Unified Conversion Name for a Conversions Source (Input Table)
and then use the Output table for analytic purposes.
How the tool work
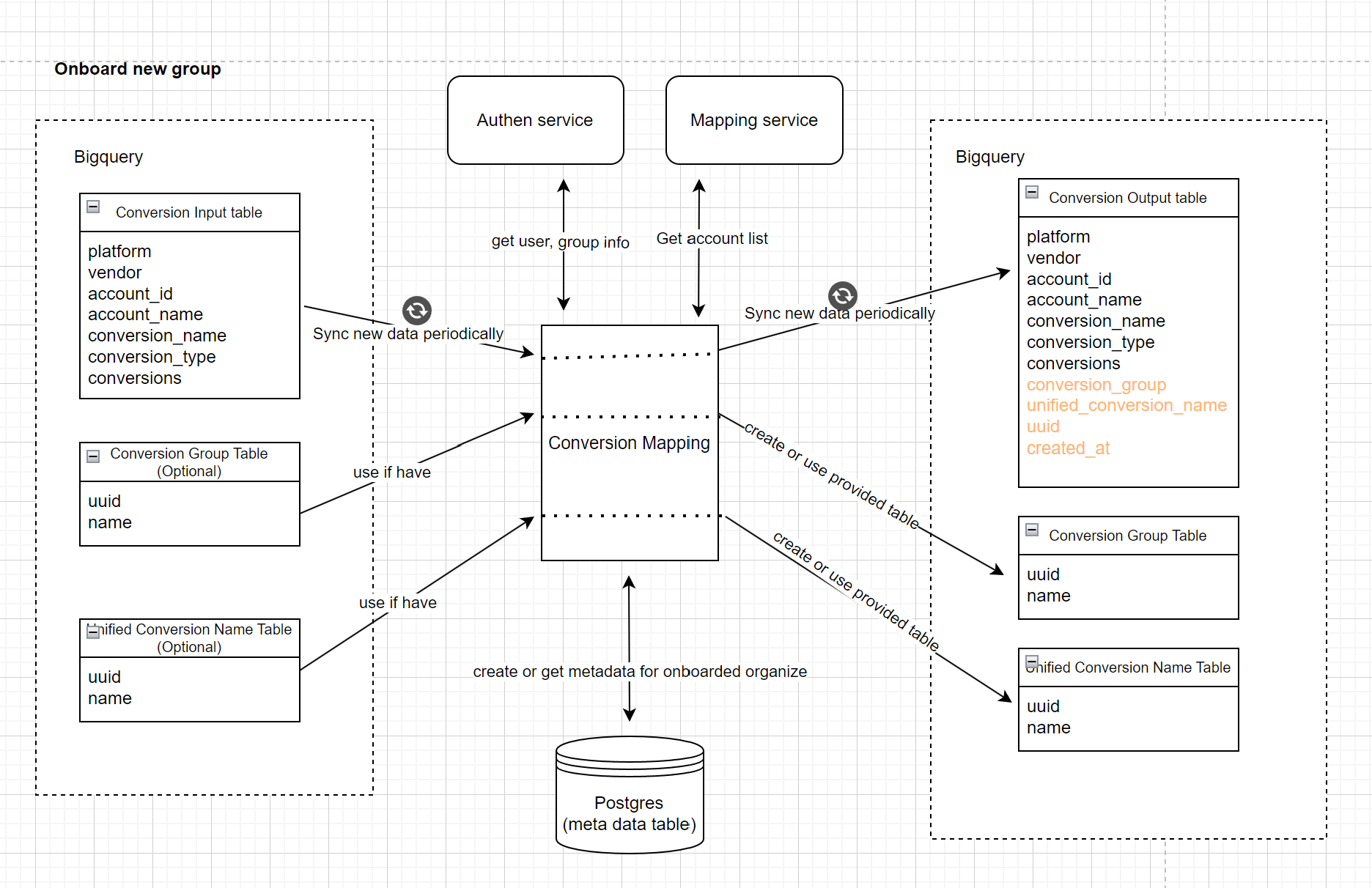
Step1: Onboard new group
User provide input table , conversion group table (optional), unified conversion name table(optional)
the tool will create output table,conversion group table, unified conversion name table. It also creates
metadata for onboarded group in postgres
Detail onboard API Endpoint:
curl --location 'http://<TOOL_URL>/admin/onboard/<org_id>' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer <token>' \ --data '{ "parent_org_id": "<parent_org_id>" "input_table": "<project_id>.<dataset>.<table_id>", "out_table": "<project_id>.<dataset>.<table_id>" }'
PROD URL: https://mapping-tool.datapal.ai
DEV URL: https://mapping-tool-api-dev-unified.datapal.ai
Request body example
{ "input_table": "datapal-dev.integration_test.integration_input_table_test", "out_table": "datapal-dev.integration_test.integration_output_table_test_3", }
Explain
parent_org_id: (optional) if specified, the parent org needs to be onboared first, then the org onboard will use table names of parent org
input_table: (required) Table contains input data with required fields as below image
out_table (optional): Output table of tool, needed when parent_org_id is not specified
Step2: Use the tool to update conversions
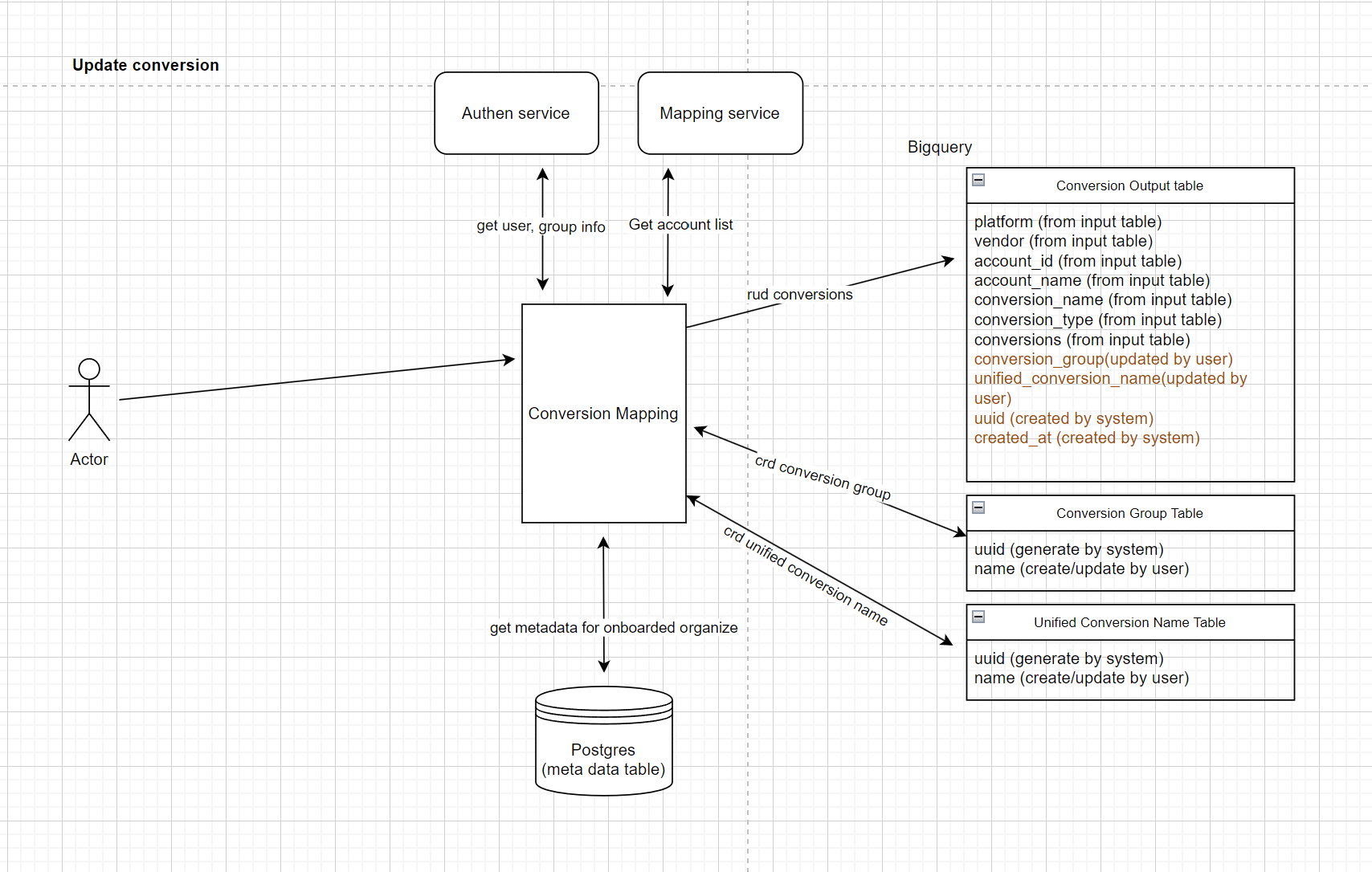
Notes:
- We sync data from input table to output table by merging with combine key (platform,account_name,conversion_name)
- Syncing data is conducted by google cloud scheduler
- We only sync fields that output table contains
# Development setup
- Clone repo and install requirements
cd ConversionTool
pip install -r requirements.txt
- Run HTTP service
The service requires Google BigQuery Authentication. Ask anh @TungPham to get the credential.
export GOOGLE_APPLICATION_CREDENTIALS=/path/to/credential.json
Also provide information about the BigQuery workspace by putting the info into .env file or os environment variable.
mv sample.env .env
Then
PYTHONPATH=. python src/main.py
or
uvicorn src.main:app
# Deployment
Build image
docker build -t cmt:<tag> .
Start docker container
docker run -d \
- p 5001:5001 \
-v /path/to/GBQ_credential.json:/cred.json \
--env-file=/path/to/env.env \
cmt:<tag>
Do a quick test/health check from host
curl http://localhost:5001/health
Expected response is {"health":"good"}
# Endpoints
# For front-end
GET /health: Health check
GET /conv/names: Get all names in dataset
PUT /conv/names: Update names in batch once unified_conversion_names and conversion_groups are filled
# For Admin
Below endpoints are specifically designed as workarounds for solving database/initial issues when the service starts first time.
PUT /conv/backfill-id: Auto add UUID to records (names) if missed.
PUT /conv/name-schema: Create or update the table schema.
........TO BE UPDATED........
Integration Test with docker-compose cd src/conversion_mapping
docker-compose up